Производительность при инференсе LLM: оптимизация на уровне модели
Поговорим о производительности инференса LLM: от механики модели и KV cache до оптимизаций attention, памяти, latency и экономики production-запуска
LLM давно перестали быть только исследовательскими моделями и экспериментами в ноутбуке. Сегодня их встраивают в продукты, внутренние ассистенты, RAG-системы, агентные контуры, инструменты поддержки, аналитики и разработки. Но когда такая система доходит до production-нагрузки, выясняется, что качество ответа — это только часть задачи.
Вторая часть — инференс: насколько быстро модель отвечает, сколько запросов выдерживает, сколько памяти требует, на каком железе запускается, какие задержки видит пользователь и во что все это обходится бизнесу.
В этой статье разберем инференс как production-задачу: механику prefill и decoding, KV cache и attention, оптимизации модели, параллелизацию между GPU, фреймворки, управление нагрузкой и экономику эксплуатации больших моделей.
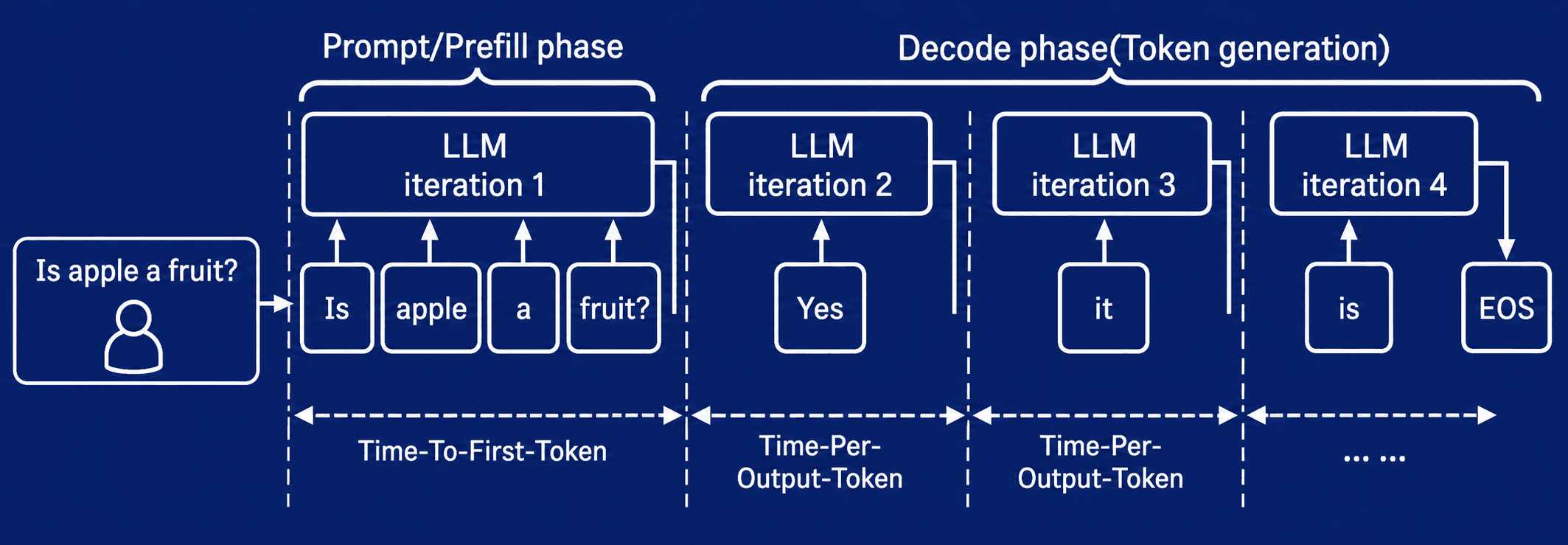
Две фазы инференса LLM. На prefill модель обрабатывает входной контекст и готовит состояние для ответа; на decode генерирует токены последовательно, поэтому задержка и работа с памятью становятся критичными.
Механика инференса LLM: почему генерация упирается в память и задержку
Инференс LLM глобально делится на две фазы: prefill и decoding.
На фазе prefill модель обрабатывает входные токены и вычисляет промежуточное состояние. В контексте attention это ключи и значения: K и V. Они дальше используются при генерации ответа. Поскольку вся входная последовательность уже известна, операции на этой фазе хорошо параллелятся и позволяют эффективно загрузить GPU.
На фазе decoding модель генерирует выходные токены по одному. Каждый следующий токен зависит от предыдущего состояния, поэтому генерация становится последовательной. Именно здесь часто возникает главное узкое место: не вычислительные ядра GPU, а пропускная способность памяти. GPU может быть мощным, но если данные не успевают подвозиться из памяти, ядра простаивают.
Поэтому большая часть оптимизаций инференса направлена не просто на «ускорить модель», а на конкретные узкие места: KV cache, attention, память, batching, параллельность, меж-GPU обмен и задержки под нагрузкой.
KV cache: зачем он нужен и почему быстро съедает VRAM
Первая важная оптимизация — KV cache. Без кэша модель на каждом шаге генерации заново пересчитывала бы key/value-тензоры для уже обработанных токенов. KV cache позволяет сохранить эти тензоры в памяти GPU и переиспользовать их на следующих шагах.
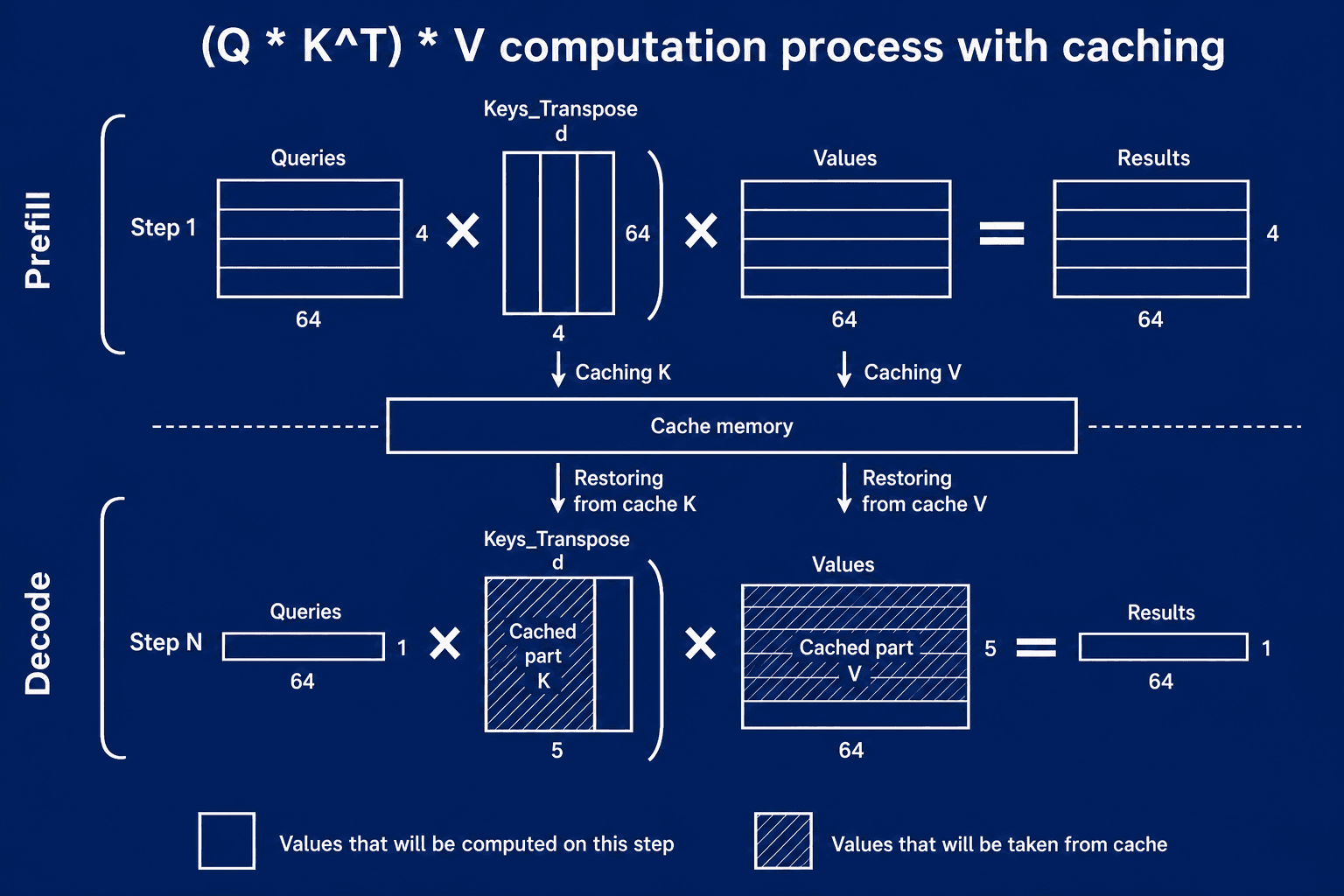
Процесс вычисления внимания с кэшированием. На фазе prefill K и V вычисляются и помещаются в кэш. На фазе decode они извлекаются из кэша, а заново считается только информация для нового токена.
У LLM есть два основных потребителя памяти GPU:
- веса модели;
- KV cache.
С весами все относительно просто. Если модель содержит 7 млрд параметров и загружена в FP16 или BF16, она займет примерно:
7 млрд * sizeof(FP16) ≈ 14 GB
KV cache считать сложнее. Для Multi-Head Attention размер KV cache на один токен можно оценить так:
Size of KV cache per token in bytes =
2 * num_layers * num_heads * head_dim * precision_in_bytes
2 * num_layers * num_heads * head_dim * precision_in_bytes
Для запроса целиком:
Size of KV cache per request in bytes =
sequence_length * 2 * num_layers * num_heads * head_dim * sizeof(FP16)
sequence_length * 2 * num_layers * num_heads * head_dim * sizeof(FP16)
Коэффициент 2 здесь появляется из-за двух матриц: key и value.
Например, для модели уровня Llama 2 7B в 16-битной точности запрос на 4000 токенов может требовать порядка 2 GB KV cache. Это только один запрос. Если таких запросов десятки или сотни, KV cache становится одним из главных ограничителей параллельности.
Оптимизации модели: attention-архитектура, длинный контекст и сжатие
Attention-архитектуры: как MHA, MQA, GQA и MLA меняют требования к памяти
Размер KV cache напрямую зависит от архитектуры attention. Поэтому при выборе модели важно смотреть не только на число параметров, но и на то, как в ней устроено внимание.

Классический MHA дает хорошее качество, но хранит много данных. MQA резко снижает память, потому что оставляет одну key/value-голову, но платит качеством. GQA стал практичным компромиссом: несколько query-голов используют одну key/value-группу.
MLA, подход DeepSeek, идет дальше: вместо хранения полного K/V используется сжатое латентное представление. Это особенно полезно, когда система упирается в VRAM. Но если узкое место уже в вычислениях, дополнительное сжатие и восстановление может стать новым overhead.

Как разные attention-архитектуры уменьшают объем KV cache. MHA хранит отдельные K/V для каждой головы, MQA использует общий набор, GQA делит головы на группы, а MLA кэширует сжатое латентное представление.
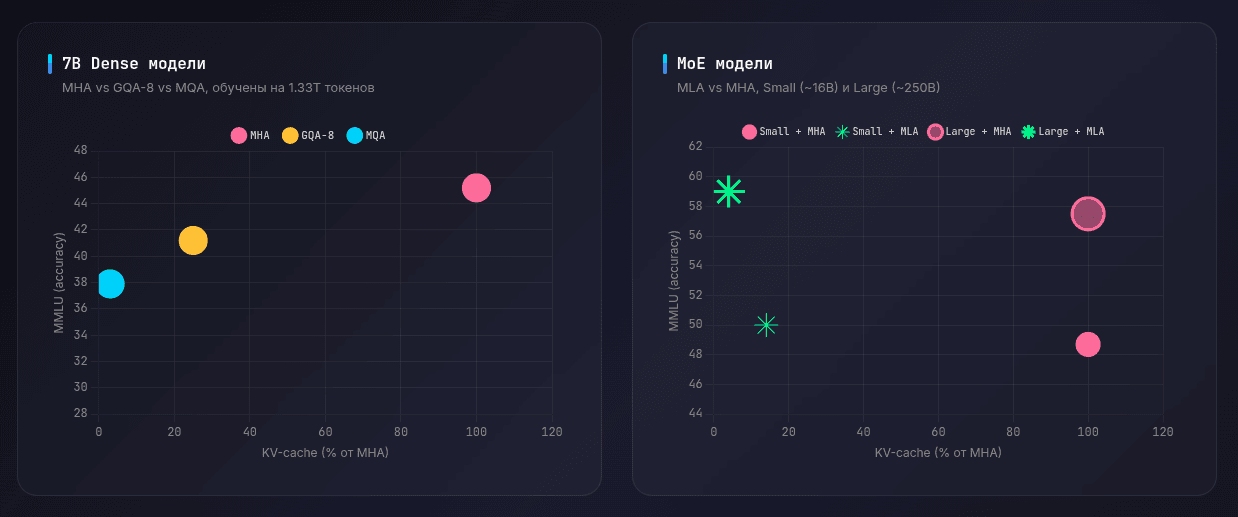
Компромисс между размером KV cache и качеством. Сильное сжатие кэша снижает требования к памяти, но разные архитектуры по-разному платят за это качеством на бенчмарках.
Главный вывод: архитектура attention может менять требования к памяти радикально. Две модели похожего размера могут вести себя совершенно по-разному, если у них разные MHA/MQA/GQA/MLA-схемы.
Оптимизации внимания для длинного контекста: как снизить квадратичную сложность
KV cache — не единственная проблема. У классического attention есть еще одна фундаментальная особенность: вычислительная сложность растет квадратично с длиной контекста. Чем длиннее контекст, тем дороже становится attention.
Для борьбы с этим используют несколько классов оптимизаций.
Linear Attention заменяет softmax и скалярное умножение функцией, которую можно применять к query и key отдельно. Сложность падает до O(n), но подобрать функцию без потери качества сложно.
Low-Rank Attention использует проекцию в меньшую размерность. Идея в том, что матрица attention на практике часто имеет низкий ранг: значительная часть информации содержится в небольшом числе компонент. Тогда K и V можно сжать по длине последовательности из n в k, где k << n, и получить матрицу attention n × k вместо n × n. Сложность становится O(n * k).
Sparse Attention делает attention разреженным: токен смотрит не на все остальные токены, а только на подмножество по заданному паттерну. Сложность тоже падает до O(n * k), где k — размер паттерна.
Sliding Window Attention: ограничиваем внимание локальным окном
Самый понятный пример Sparse Attention — Sliding Window Attention. Каждый токен видит только соседние токены в окне, а не весь контекст.
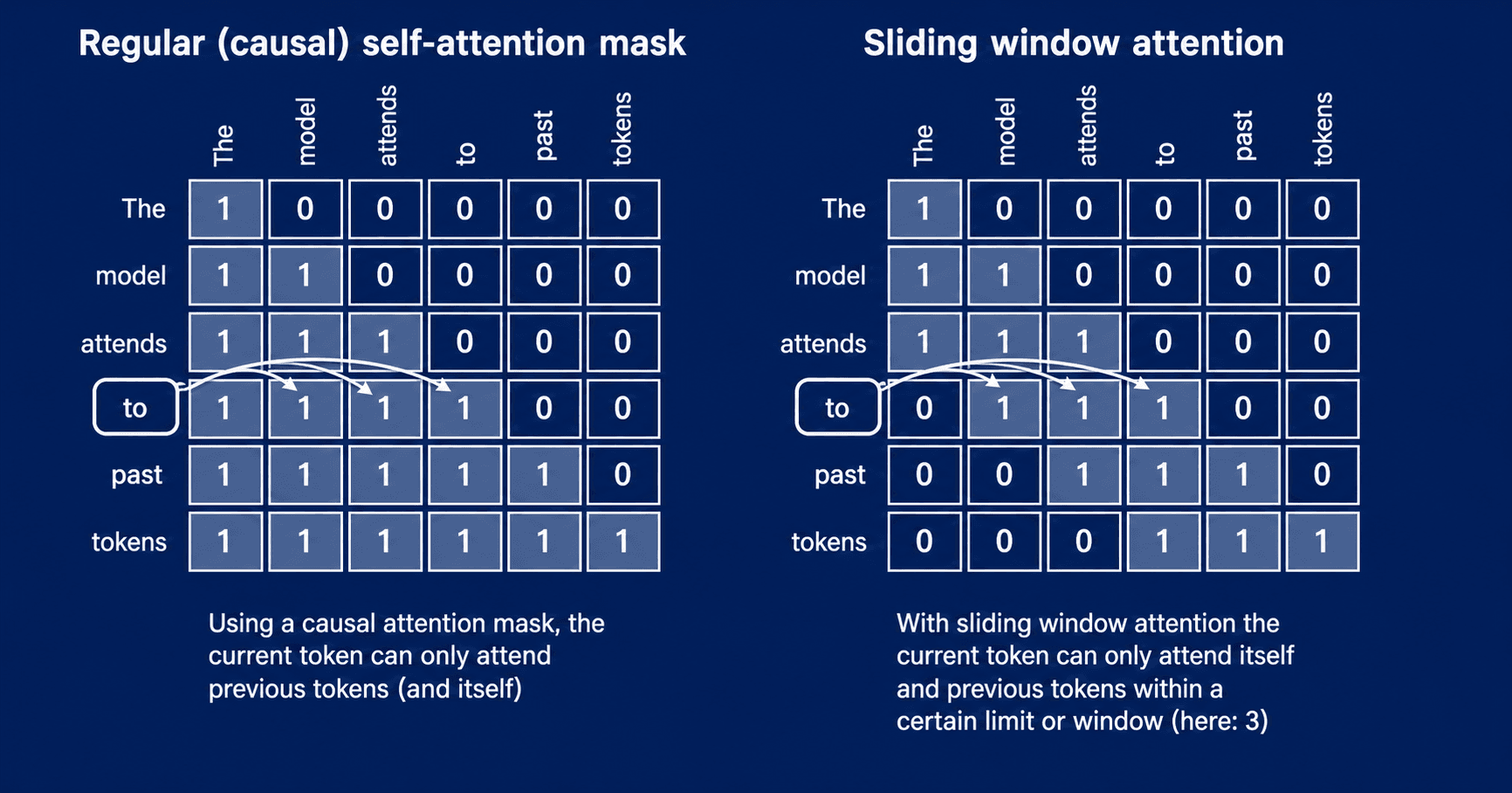
Sliding Window Attention ограничивает область внимания локальным окном. Каждый токен учитывает только ближайших соседей, поэтому стоимость вычислений растет медленнее, чем при полном attention.
На практике sliding window часто используют гибридно: часть слоев работает с полным attention, часть — со скользящим окном. Так можно сохранить доступ к дальнему контексту, но уменьшить стоимость вычислений и объем KV cache.
DeepSeek Sparse Attention: выбираем релевантные токены до полного attention
DeepSeek Sparse Attention использует более динамический подход. Вместо фиксированного окна там есть индексатор и селектор. Они заранее выбирают, какие токены релевантны, и только их отправляют дальше в attention.
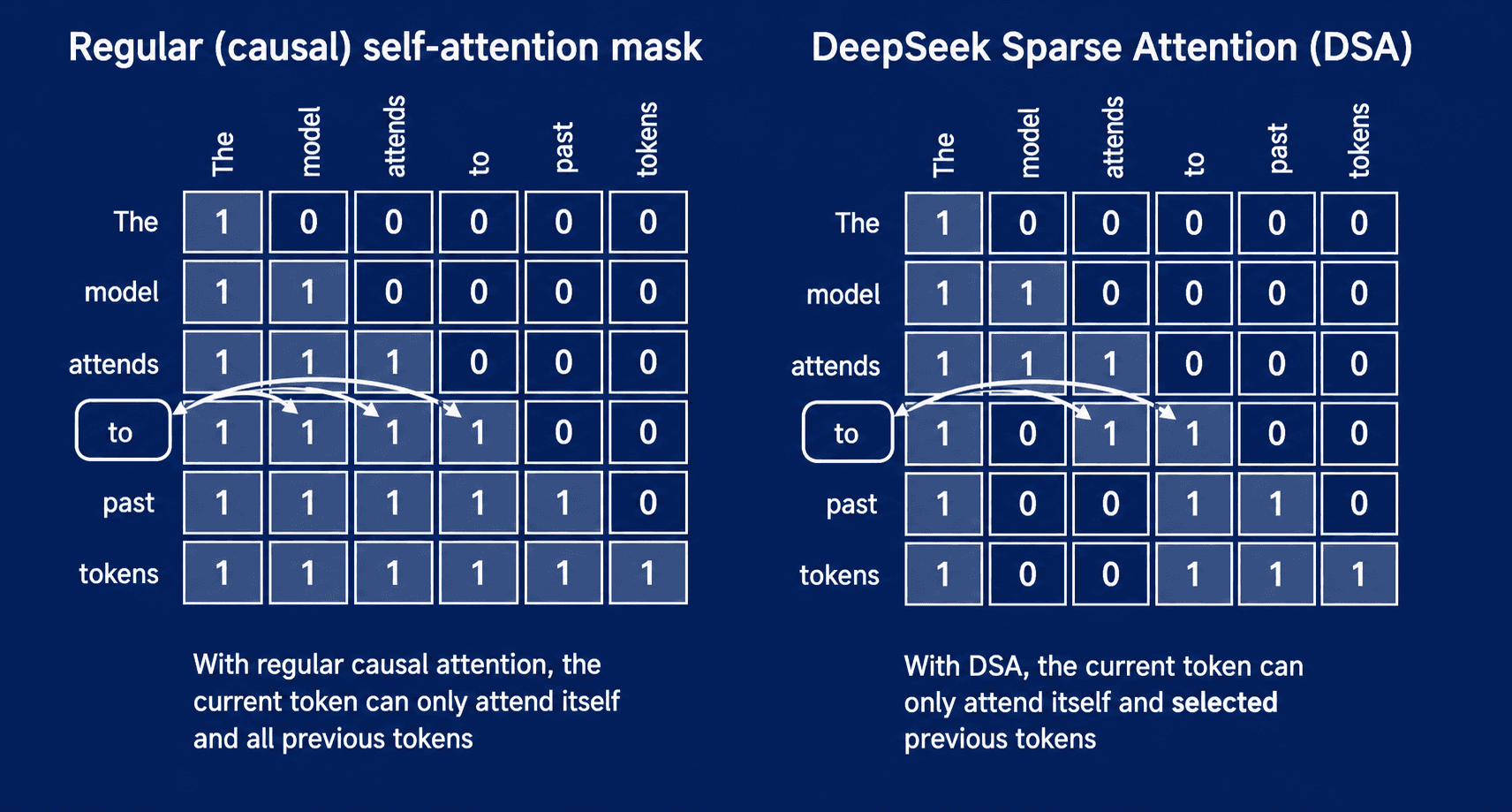
Разреженное внимание в DeepSeek выбирает часть токенов перед основным attention. Такой подход уменьшает число сравнений, сохраняя доступ к наиболее релевантным позициям контекста.
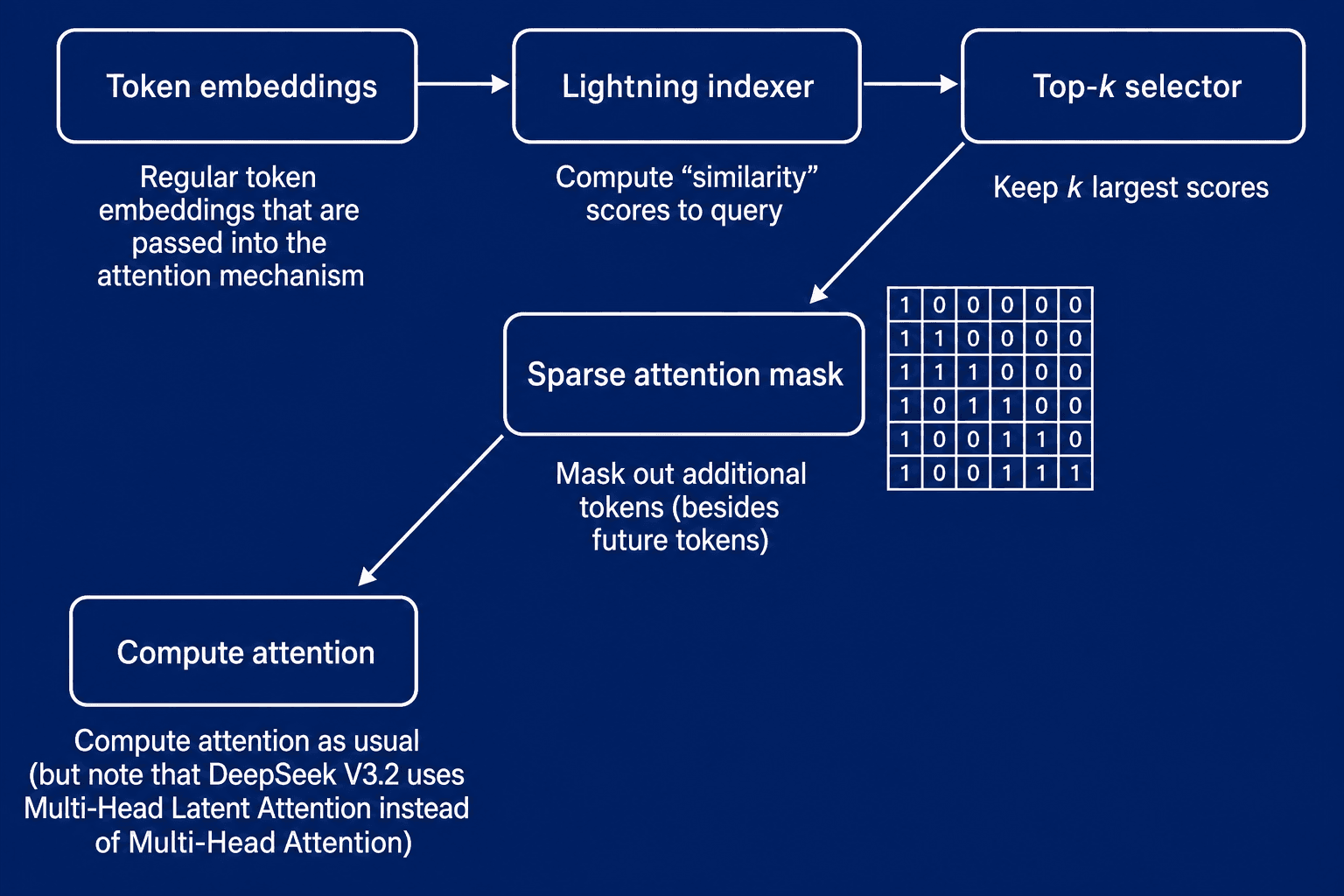
Схема DeepSeek Sparse Attention: индексатор и селектор заранее выбирают важные токены, после чего полный attention применяется только к сокращенному набору.
Это быстрый отбор токенов перед дорогим attention. Подход хорошо совпадает с общей философией DeepSeek: использовать низкоранговые и разреженные представления там, где можно сэкономить память и вычисления без существенной потери качества.
Сравнение моделей: почему число параметров ничего не гарантирует
Теперь можно применить эти признаки к выбору конкретной модели. Снаружи модели могут выглядеть близко по качеству, но внутри отличаться именно теми параметрами, которые определяют стоимость инференса.
Для практического сравнения возьмем несколько моделей с разной архитектурой: Qwen3-30B-A3B, gpt-oss-20b, Phi-4-reasoning и GLM-4.7-Flash. Они близки по уровню бенчмарков, но отличаются по attention и типу архитектуры.
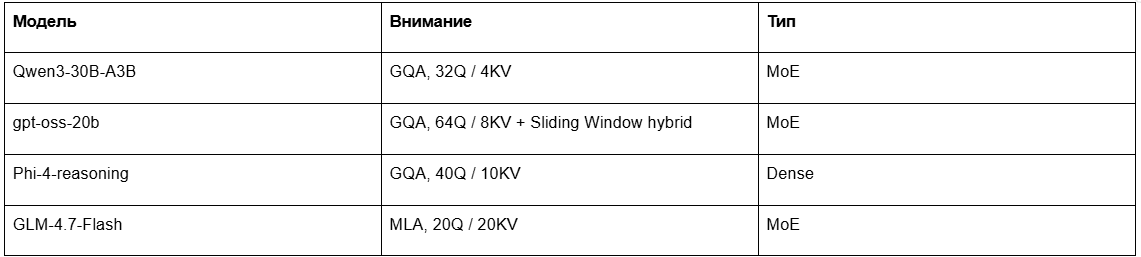
У этих моделей может быть похожий уровень качества, но сильно разный профиль потребления памяти. Например, число KV-голов прямо влияет на объем KV cache. А наличие MLA или sliding window может заметно снизить требования к памяти.
Модели близкого класса могут различаться по устройству attention. Число query- и KV-голов, MoE/Dense-архитектура и sliding window напрямую влияют на память и скорость.
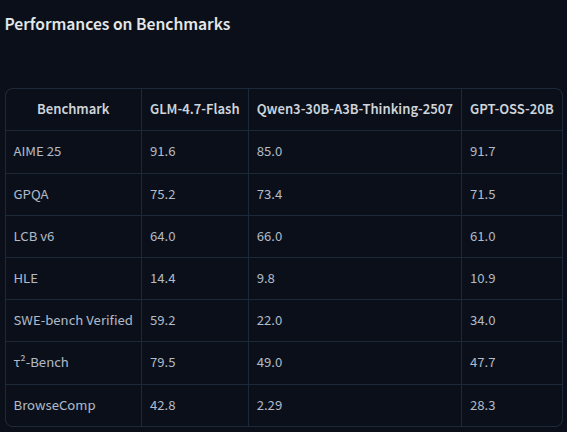
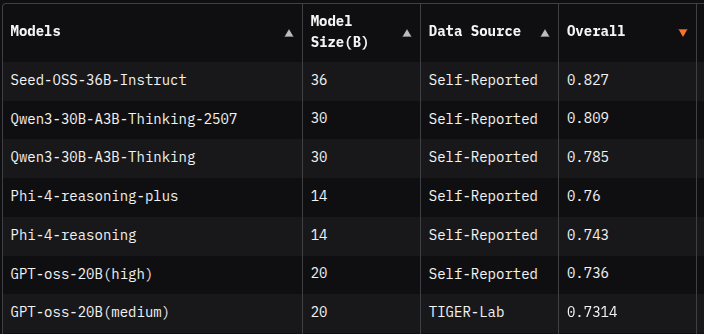
Сравнение моделей по бенчмаркам показывает, что похожее качество не означает одинаковую стоимость инференса: архитектура и кэш могут различаться сильнее, чем итоговые баллы.
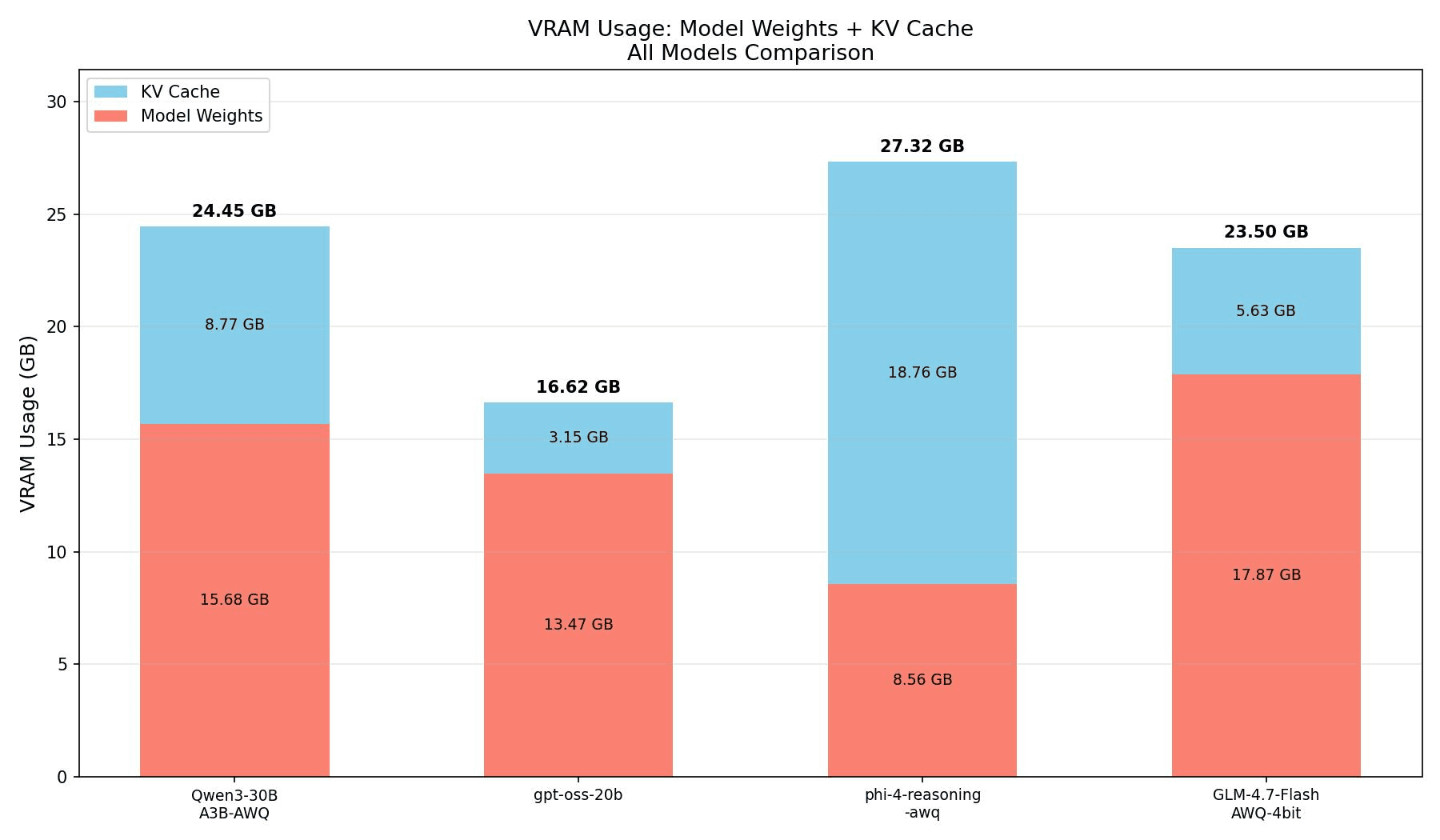
Оценка VRAM для моделей с разной attention-архитектурой. Даже при сопоставимом качестве профиль памяти может отличаться из-за KV cache и активных экспертов.
Отсюда ключевой практический вывод: выбор модели — это не выбор «модель на 30B против модели на 70B». Нужно смотреть на архитектуру внимания, наличие оптимизаций, MoE или Dense, число KV-голов, поддержку длинного контекста, квантизацию и реальное потребление VRAM под ожидаемой нагрузкой.
Сжатие моделей: квантизация уменьшает память, дистилляция переносит знания
Следующий большой класс оптимизаций — сжатие модели.
Квантизация снижает точность весов и активаций. Это уменьшает память и ускоряет работу там, где система упирается в пропускную способность памяти. Практический ориентир — 4-битная квантизация. Ниже обычно начинается слишком заметная деградация качества, а 4 бита часто дают приемлемый компромисс.
Дистилляция переносит знания из большой модели в меньшую. Большая модель-учитель генерирует ответы и вероятностные распределения, а маленькая м
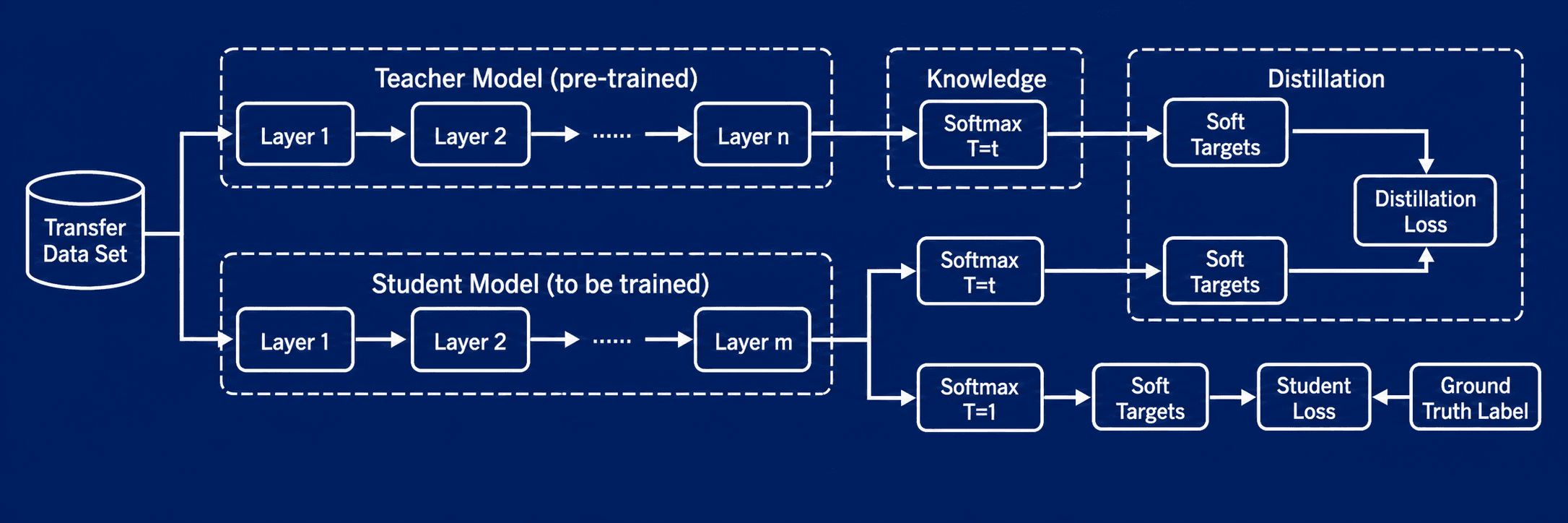
Два способа уменьшить стоимость инференса. Квантизация снижает точность весов и экономит память, а дистилляция переносит поведение большой модели в меньшую.
Но у дистилляции есть важное ограничение: лицензии. Многие современные модели запрещают использовать их ответы для обучения других моделей. Поэтому модель-учителя нужно выбирать внимательно.
Вывод по оптимизациям модели: выбирать нужно архитектуру, а не только размер
Модель нельзя выбирать только по поставщику, количеству параметров или общему leaderboard-у. Нужно учитывать:
- архитектуру attention: MHA, MQA, GQA, MLA;
- наличие оптимизаций attention;
- MoE или Dense;
- число KV-голов;
- требования к KV cache;
- поддержку квантизации;
- качество маленьких моделей на вашей задаче;
- реальные latency/throughput-замеры.
Иначе можно выбрать модель, которая выглядит хорошо в benchmark-е, но плохо помещается в production-экономику.
В этой части мы разобрали оптимизации на уровне самой модели: какие архитектурные решения влияют на объем вычислений, потребление памяти и итоговую стоимость инференса, и почему эти параметры важно учитывать еще до выбора конкретного deployment-сценария. Во второй части перейдем на следующий уровень и посмотрим, как те же ограничения проявляются уже в железе: какие GPU и серверные конфигурации нужны для разных классов моделей, где упираемся в память и пропускную способность, и как это влияет на производительность и экономику production-инференса.